第1节、java基础
第1节、java基础
1.0 概念
说一下Java的特点
主要有以下的特点:
- 平台无关性:Java的“编写一次,运行无处不在”哲学是其最大的特点之一。Java编译器将源代码编译成字节码(bytecode),该字节码可以在任何安装了Java虚拟机(JVM)的系统上运行。
- 面向对象:Java是一门严格的面向对象编程语言,几乎一切都是对象。面向对象编程(OOP)特性使得代码更易于维护和重用,包括类(class)、对象(object)、继承(inheritance)、多态(polymorphism)、抽象(abstraction)和封装(encapsulation)。
- 内存管理:Java有自己的垃圾回收机制,自动管理内存和回收不再使用的对象。这样,开发者不需要手动管理内存,从而减少内存泄漏和其他内存相关的问题。
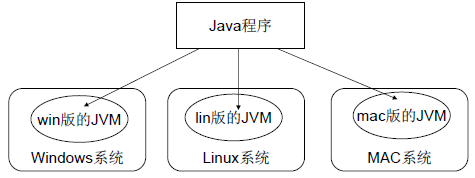
#Java为什么是跨平台的?
Java 能支持跨平台,主要依赖于 JVM 关系比较大。
JVM也是一个软件,不同的平台有不同的版本。我们编写的Java源码,编译后会生成一种 .class 文件,称为字节码文件。Java虚拟机就是负责将字节码文件翻译成特定平台下的机器码然后运行。也就是说,只要在不同平台上安装对应的JVM,就可以运行字节码文件,运行我们编写的Java程序。
而这个过程中,我们编写的Java程序没有做任何改变,仅仅是通过JVM这一”中间层“,就能在不同平台上运行,真正实现了”一次编译,到处运行“的目的。
JVM是一个”桥梁“,是一个”中间件“,是实现跨平台的关键,Java代码首先被编译成字节码文件,再由JVM将字节码文件翻译成机器语言,从而达到运行Java程序的目的。
编译的结果不是生成机器码,而是生成字节码,字节码不能直接运行,必须通过JVM翻译成机器码才能运行。不同平台下编译生成的字节码是一样的,但是由JVM翻译成的机器码却不一样。
所以,运行Java程序必须有JVM的支持,因为编译的结果不是机器码,必须要经过JVM的再次翻译才能执行。即使你将Java程序打包成可执行文件(例如 .exe),仍然需要JVM的支持。
跨平台的是Java程序,不是JVM。JVM是用C/C++开发的,是编译后的机器码,不能跨平台,不同平台下需要安装不同版本的JVM。
#JVM、JDK、JRE三者关系?
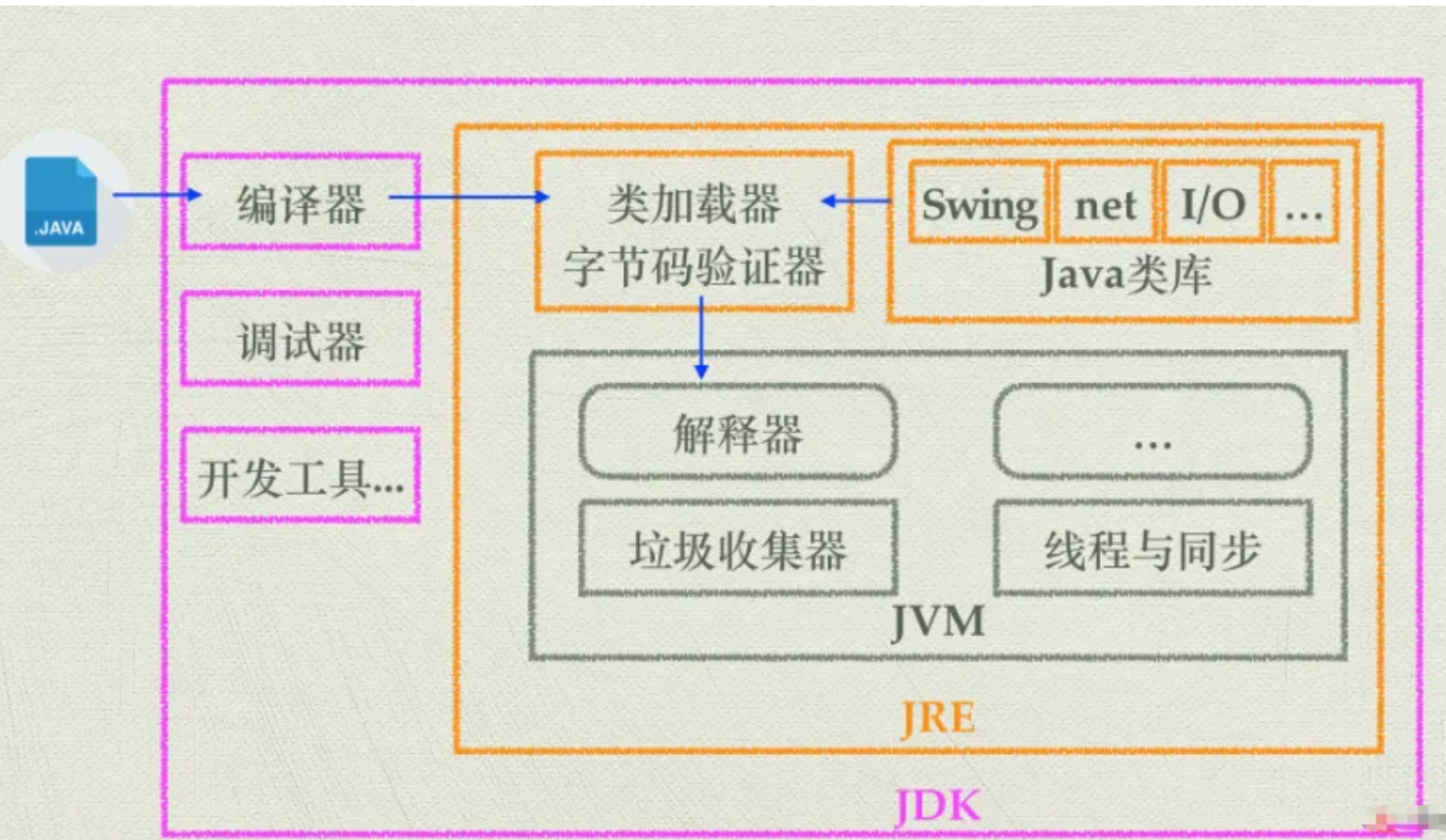
它们之间的关系如下:
- JVM是Java虚拟机,是Java程序运行的环境。它负责将Java字节码(由Java编译器生成)解释或编译成机器码,并执行程序。JVM提供了内存管理、垃圾回收、安全性等功能,使得Java程序具备跨平台性。
- JDK是Java开发工具包,是开发Java程序所需的工具集合。它包含了JVM、编译器(javac)、调试器(jdb)等开发工具,以及一系列的类库(如Java标准库和开发工具库)。JDK提供了开发、编译、调试和运行Java程序所需的全部工具和环境。
- JRE是Java运行时环境,是Java程序运行所需的最小环境。它包含了JVM和一组Java类库,用于支持Java程序的执行。JRE不包含开发工具,只提供Java程序运行所需的运行环境。
我们下载一个JDK8,然后打开文件夹,最外边的一层就是JDK,如下图所示

JDK的文件夹里边包含了一个JRE,JRE的文件夹里边包含两部分,如下图
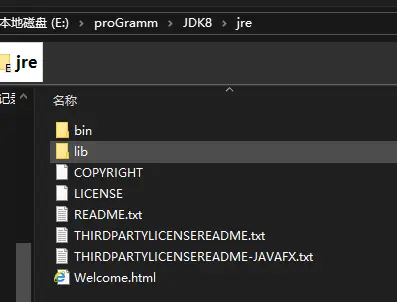
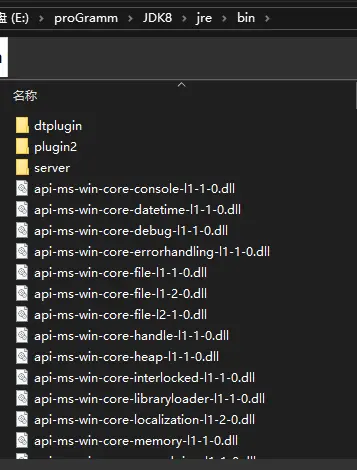
一部分就是lib文件夹,里边是java的一些类库,而bin文件夹里边全都是dll文件,其中还有一个就是上图所写的jvm.dll,为什么是dll文件呢,因为JVM就是使用C/C++写的,所以说java又叫C加加减减。
#为什么Java解释和编译都有?
首先在Java经过编译之后生成字节码文件,接下来进入JVM中,就有两个步骤编译和解释。 如下图:
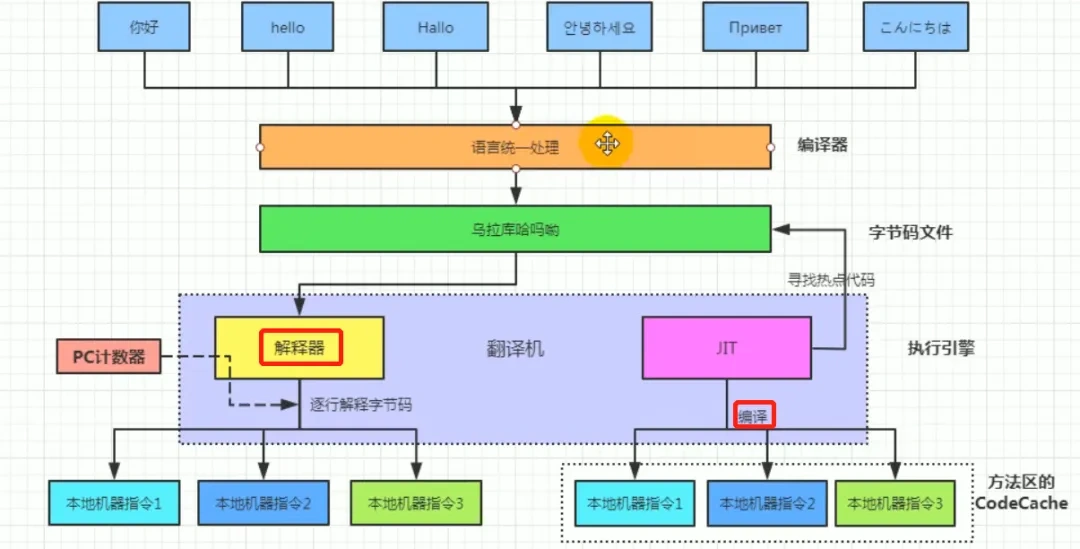
编译性:
- Java源代码首先被编译成字节码,JIT 会把编译过的机器码保存起来,以备下次使用。
解释性:
- JVM中一个方法调用计数器,当累计计数大于一定值的时候,就使用JIT进行编译生成机器码文件。否则就是用解释器进行解释执行,然后字节码也是经过解释器进行解释运行的。
所以Java既是编译型也是解释性语言,默认采用的是解释器和编译器(JIT)混合的模式。
#jvm是什么
JVM是 java 虚拟机,主要工作是解释自己的指令集(即字节码)并映射到本地的CPU指令集和OS的系统调用。
JVM屏蔽了与操作系统平台相关的信息,使得Java程序只需要生成在Java虚拟机上运行的目标代码(字节码),就可在多种平台上不加修改的运行,这也是Java能够“一次编译,到处运行的”原因。
#编译型语言和解释型语言的区别?
编译型语言和解释型语言的区别在于:
- 编译型语言:在程序执行之前,整个源代码会被编译成机器码或者字节码,生成可执行文件。执行时直接运行编译后的代码,速度快,但跨平台性较差。
- 解释型语言:在程序执行时,逐行解释执行源代码,不生成独立的可执行文件。通常由解释器动态解释并执行代码,跨平台性好,但执行速度相对较慢。
- 典型的编译型语言如C、C++,典型的解释型语言如Python、JavaScript。
#Python和Java区别是什么?
- Java是一种已编译的编程语言,Java编译器将源代码编译为字节码,而字节码则由Java虚拟机执行
- python是一种解释语言,翻译时会在执行程序的同时进行翻译。
1.1 基本数据类型
()为什么推荐使用包装类而不是基本数据类型?
因为包装类的初始值是null而不是0,故可以区分已经赋值和未赋值的情况。如果是基本数据类型,因为初始值是0,可能无法区分赋的值是0还是说没有赋值。在需要严格区分数据是否赋值的环境下,使用包装类,其中阿里巴巴的java开发手册就规定,数据字段必须使用包装类。
()基本数据类型和包装类区别?
1.初始值:int是基本数据类型,Integer是int的封装类,是引用类型。int默认值是0,而Integer默认值是nul,所以Integer能区分出0和null的情况。一旦java看到nul,就知道这个引用还没有指向某个对象,再任何引用使用前,必须为其指定一个对象,否则会报错
2.内存空间:基本数据类型在声明时系统会自动给它分配空间,而引用类型声明时只是分配了引用空间必须通过实例化开辟数据空间之后才可以赋值。数组对象也是一个引用对象,将一个数组赋值给另个数组时只是复制了一个引用,所以通过某一个数组所做的修改在另一个数组中也看的见。
()boolean在虚拟机中占用的内存?
虽然定义了boolean这种数据类型,但是只对它提供了非常有限的支持。在|ava虚拟机中没有任何供boolean值专用的字节码指令,ava语言表达式所操作的boolean值,在编译之后都使用lava虚拟机中的int数据类型来代替,而boolean数组将会被编码成ava虚拟机的byte数组,每个元素boolean元素占8位。
这样我们可以得出boolean类型占了单独使用是4个字节,在数组中又是1个字节。使用int的原因是,对于当下32位的处理器(CPU)来说,一次处理数据是32位(这里不是指的是32/64位系统,而是指CPU硬件层面),具有高效存取的特点。
[!NOTE]
如果为了追求极值的性能,是否可以使用 byte 值的0和1来替代boolean??建议不这么做,如果是C/C++,会推荐这么做,但是这里是java。
Boolean包装类的初始值是 null
()自动装箱与拆箱(经典题目)
面试题1:以下代码会输出什么?
public class Main{
public static void main(string[] args) {
Integer i1= 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
System.out.println(i1==i2); // true
System.out.println(i3==i4); // false
}
}运行结果
true
false自动装箱的源码如下
public static Integer value0f(int i)
{
if(i >=-128 && i<= IntegerCache.high)
return IntegerCache.cache[i + 128];
else
return new Integer(i);
}从这2段代码可以看出,在通过value0f方法创建Integer对象的时候,如果数值在[-128,127]之间便返回指向IntegerCache.cache中已经存在的对象的引用;否则创建一个新的Integer对象。
上面的代码中i1和i2的数值为100,因此会直接从cache中取已经存在的对象,所以i1和i2指向的是同一个对象,而i3和i4则是分别指向不同的对象。
[!IMPORTANT]
总结:Integer 和 int 不一样的地方在于,Integer 是对象,int是值。使用==进行比较的时候,如果是值类型,那么直接比较值大小;如果是引用类型,则比较引用的地址,例如 Integer 。
照这个说法,Integer(100)和Integr(100)也不应该相等,但是java对[-128,127]区间做了缓存,让这些区间的 Integer 指向同一个对象。
[!NOTE]
Double没有做这样的缓存,因为Integer在区间内个数固定,Double包装类这不固定。
八种基本的数据类型
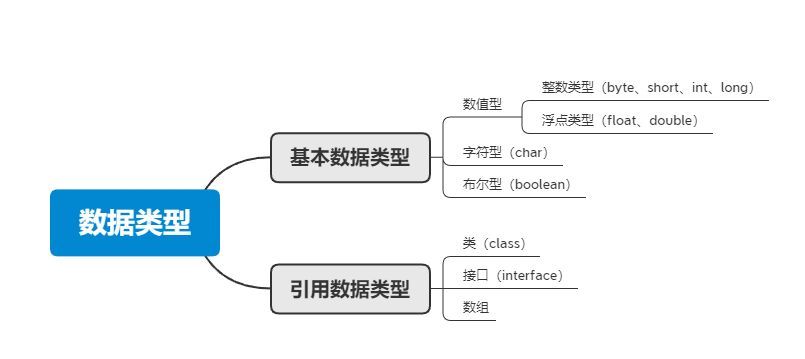
Java支持数据类型分为两类: 基本数据类型和引用数据类型。
基本数据类型共有8种,可以分为三类:
数值型:整数类型(byte、short、int、long)和浮点类型(float、double)
字符型:char
布尔型:boolean
img
8种基本数据类型的默认值、位数、取值范围,如下表所示:
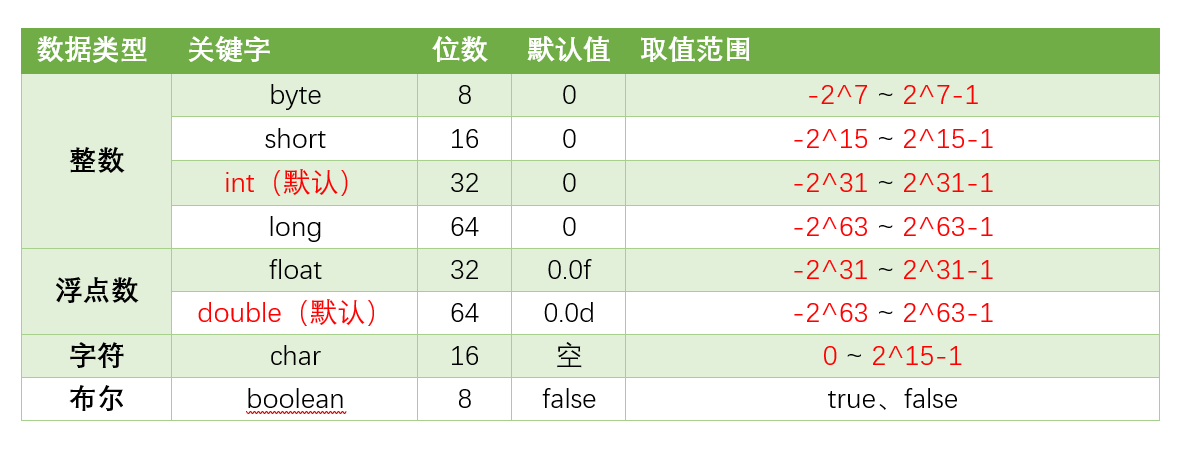
Float和Double的最小值和最大值都是以科学记数法的形式输出的,结尾的“E+数字”表示E之前的数字要乘以10的多少倍。比如3.14E3就是3.14×1000=3140,3.14E-3就是3.14/1000=0.00314。
注意一下几点:
- java八种基本数据类型的字节数:1字节(byte、boolean)、 2字节(short、char)、4字节(int、float)、8字节(long、double)
- 浮点数的默认类型为double(如果需要声明一个常量为float型,则必须要在末尾加上f或F)
- 整数的默认类型为int(声明Long型在末尾加上l或者L)
- 八种基本数据类型的包装类:除了char的是Character、int类型的是Integer,其他都是首字母大写
- char类型是无符号的,不能为负,所以是0开始的
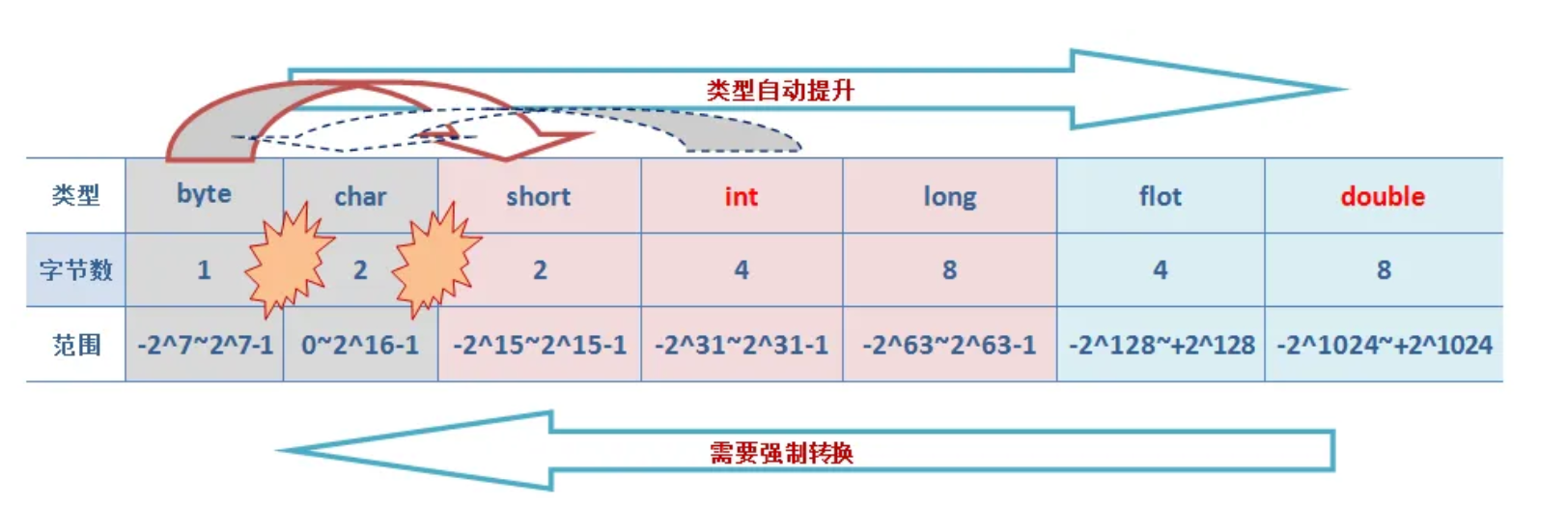
#long和int可以互转吗 ?
可以的,Java中的long和int可以相互转换。由于long类型的范围比int类型大,因此将int转换为long是安全的,而将long转换为int可能会导致数据丢失或溢出。
将int转换为long可以通过直接赋值或强制类型转换来实现。例如:
int intValue = 10;
long longValue = intValue; // 自动转换,安全的将long转换为int需要使用强制类型转换,但需要注意潜在的数据丢失或溢出问题。
例如:
long longValue = 100L;
int intValue = (int) longValue; // 强制类型转换,可能会有数据丢失或溢出在将long转换为int时,如果longValue的值超出了int类型的范围,转换结果将是截断后的低位部分。因此,在进行转换之前,建议先检查longValue的值是否在int类型的范围内,以避免数据丢失或溢出的问题。
#数据类型转换方式你知道哪些?
- 自动类型转换(隐式转换):当目标类型的范围大于源类型时,Java会自动将源类型转换为目标类型,不需要显式的类型转换。例如,将
int转换为long、将float转换为double等。 - 强制类型转换(显式转换):当目标类型的范围小于源类型时,需要使用强制类型转换将源类型转换为目标类型。这可能导致数据丢失或溢出。例如,将
long转换为int、将double转换为int等。语法为:目标类型 变量名 = (目标类型) 源类型。 - 字符串转换:Java提供了将字符串表示的数据转换为其他类型数据的方法。例如,将字符串转换为整型
int,可以使用Integer.parseInt()方法;将字符串转换为浮点型double,可以使用Double.parseDouble()方法等。 - 数值之间的转换:Java提供了一些数值类型之间的转换方法,如将整型转换为字符型、将字符型转换为整型等。这些转换方式可以通过类型的包装类来实现,例如
Character类、Integer类等提供了相应的转换方法。
#类型互转会出现什么问题吗?
- 数据丢失:当将一个范围较大的数据类型转换为一个范围较小的数据类型时,可能会发生数据丢失。例如,将一个
long类型的值转换为int类型时,如果long值超出了int类型的范围,转换结果将是截断后的低位部分,高位部分的数据将丢失。 - 数据溢出:与数据丢失相反,当将一个范围较小的数据类型转换为一个范围较大的数据类型时,可能会发生数据溢出。例如,将一个
int类型的值转换为long类型时,转换结果会填充额外的高位空间,但原始数据仍然保持不变。 - 精度损失:在进行浮点数类型的转换时,可能会发生精度损失。由于浮点数的表示方式不同,将一个单精度浮点数(
float)转换为双精度浮点数(double)时,精度可能会损失。 - 类型不匹配导致的错误:在进行类型转换时,需要确保源类型和目标类型是兼容的。如果两者不兼容,会导致编译错误或运行时错误。
#为什么用 bigDecimal 不用double ?
double会出现精度丢失的问题,double执行的是二进制浮点运算,二进制有些情况下不能准确的表示一个小数,就像十进制不能准确的表示1/3(1/3=0.3333...),也就是说二进制表示小数的时候只能够表示能够用1/(2n)的和的任意组合,但是0.1不能够精确表示,因为它不能够表示成为1/(2n)的和的形式。
比如:
System.out.println(0.05 + 0.01);
System.out.println(1.0 - 0.42);
System.out.println(4.015 * 100);
System.out.println(123.3 / 100);
输出:
0.060000000000000005
0.5800000000000001
401.49999999999994
1.2329999999999999可以看到在Java中进行浮点数运算的时候,会出现丢失精度的问题。那么我们如果在进行商品价格计算的时候,就会出现问题。很有可能造成我们手中有0.06元,却无法购买一个0.05元和一个0.01元的商品。因为如上所示,他们两个的总和为0.060000000000000005。这无疑是一个很严重的问题,尤其是当电商网站的并发量上去的时候,出现的问题将是巨大的。可能会导致无法下单,或者对账出现问题。
而 Decimal 是精确计算 , 所以一般牵扯到金钱的计算 , 都使用 Decimal。
import java.math.BigDecimal;
public class BigDecimalExample {
public static void main(String[] args) {
BigDecimal num1 = new BigDecimal("0.1");
BigDecimal num2 = new BigDecimal("0.2");
BigDecimal sum = num1.add(num2);
BigDecimal product = num1.multiply(num2);
System.out.println("Sum: " + sum);
System.out.println("Product: " + product);
}
}
//输出
Sum: 0.3
Product: 0.02在上述代码中,我们创建了两个BigDecimal对象num1和num2,分别表示0.1和0.2这两个十进制数。然后,我们使用add()方法计算它们的和,并使用multiply()方法计算它们的乘积。最后,我们通过System.out.println()打印结果。
这样的使用BigDecimal可以确保精确的十进制数值计算,避免了使用double可能出现的舍入误差。需要注意的是,在创建BigDecimal对象时,应该使用字符串作为参数,而不是直接使用浮点数值,以避免浮点数精度丢失。
()扩展,double如何导致小数点丢失的,而 bigDecimal 又是如何避免小数点丢失的?
因为double和float都是采用的二进制小数点记法。比如说一个二进制的 二进制的个位表示2的0次方,二进制的十位表示2的1次方,表示有几个2,11b就表示3 。
同理,这是整数部分,小数部分的0.1b就表述一个2的-1次方,而0.01b也就表示有一个2的-2次方。那0.1b也就等于1/2=0.5(10),也就是10进制的0.5 。好,那0.01b也就表示十进制的0.25,很容易理解。那么0.11b也就表示0.5+0.25=0.75,十进制的0.75 。再扩展一下,0.001b表示十进制的0.125 。实际上,如果要表示一个doubel 的小数,那就需要找到一些值他们相加最后等于这个十进制值,所以只能无限接近这个值。比如十进制的0.75就一定有一个精确的二进制表达,而其他的值,比如说0.76就不一定有二进制的精确表达。
BigDecimal底层的代码可读性不是很好,这里直接给出底层实现原理的总结:
在BigDecimal内部,它使用**一个整数数组来存储数值的每一位。**通常情况下,数组的每个元素表示一组十进制数的位数,例如,数组的第一个元素表示最低位,第二个元素表示十位,以此类推。每个数组元素都是一个32位整数,即可以存储0到2^32-1之间的数值。
例如:
- 未缩放值(Unscaled Value):使用
BigInteger存储所有有效数字的整数部分,例如123.45存储为12345。 - 标度(Scale):记录小数点后的位数,如
123.45的标度为2。数值等价于未缩放值 × 10^(-标度)
为了表示一个数值,BigDecimal还需要维护一些其他的信息,包括符号(正数、负数或零)、小数点的位置以及数值的精度。这些信息通过额外的变量来保存。
在进行数值的运算时,BigDecimal会根据操作的类型和需要的精度,对两个数值进行相应的运算,例如加法、减法、乘法和除法。运算的过程中,它会对两个数值的符号进行处理,并按照数学规则进行运算。对于除法运算,BigDecimal会通过精确的算法进行计算,避免了浮点数除法可能产生的精度损失。
不可变性与线程安全
- 每次运算生成新对象,避免并发修改,但需注意性能开销。
总结:
BigDecimal 通过整数存储和标度管理,将小数运算转化为精确的整数运算,避免二进制浮点数的固有误差,同时提供灵活的舍入控制,确保任意精度的十进制计算
#装箱和拆箱是什么?
装箱(Boxing)和拆箱(Unboxing)是将基本数据类型和对应的包装类之间进行转换的过程。
Integer i = 10; //装箱
int n = i; //拆箱自动装箱主要发生在两种情况,一种是赋值时,另一种是在方法调用的时候。
赋值时
这是最常见的一种情况,在Java 1.5以前我们需要手动地进行转换才行,而现在所有的转换都是由编译器来完成。
//before autoboxing
Integer iObject = Integer.valueOf(3);
Int iPrimitive = iObject.intValue()
//after java5
Integer iObject = 3; //autobxing - primitive to wrapper conversion
int iPrimitive = iObject; //unboxing - object to primitive conversion方法调用时
当我们在方法调用时,我们可以传入原始数据值或者对象,同样编译器会帮我们进行转换。
public static Integer show(Integer iParam){
System.out.println("autoboxing example - method invocation i: " + iParam);
return iParam;
}
//autoboxing and unboxing in method invocation
show(3); //autoboxing
int result = show(3); //unboxing because return type of method is Integershow方法接受Integer对象作为参数,当调用show(3)时,会将int值转换成对应的Integer对象,这就是所谓的自动装箱,show方法返回Integer对象,而int result = show(3);中result为int类型,所以这时候发生自动拆箱操作,将show方法的返回的Integer对象转换成int值。
[!IMPORTANT]
自动装箱的弊端
自动装箱有一个问题,那就是在一个循环中进行自动装箱操作的情况,如下面的例子就会创建多余的对象,影响程序的性能。
Integer sum = 0; for(int i=1000; i<5000; i++){ sum+=i; }上面的代码sum+=i可以看成sum = sum + i,但是+这个操作符不适用于Integer对象,首先sum进行自动拆箱操作,进行数值相加操作,最后发生自动装箱操作转换成Integer对象。其内部变化如下
int result = sum.intValue() + i; Integer sum = new Integer(result);由于我们这里声明的sum为Integer类型,在上面的循环中会创建将近4000个无用的Integer对象,在这样庞大的循环中,会降低程序的性能并且加重了垃圾回收的工作量。因此在我们编程时,需要注意到这一点,正确地声明变量类型,避免因为自动装箱引起的性能问题。
()#Java为什么要有Integer?
Integer对应是int类型的包装类,就是把int类型包装成Object对象,对象封装有很多好处,可以把属性也就是数据跟处理这些数据的方法结合在一起,比如Integer就有parseInt()等方法来专门处理int型相关的数据。
另一个非常重要的原因就是在Java中绝大部分方法或类都是用来处理类类型对象的,如ArrayList集合类就只能以类作为他的存储对象,而这时如果想把一个int型的数据存入list是不可能的,必须把它包装成类,也就是Integer才能被List所接受。所以Integer的存在是很必要的。
泛型中的应用
在Java中,泛型只能使用引用类型,而不能使用基本类型。因此,如果要在泛型中使用int类型,必须使用Integer包装类。例如,假设我们有一个列表,我们想要将其元素排序,并将排序结果存储在一个新的列表中。如果我们使用基本数据类型int,无法直接使用Collections.sort()方法。但是,如果我们使用Integer包装类,我们就可以轻松地使用Collections.sort()方法。
[!NOTE]
实际上就是Integer在内部实现了比较接口
Comparable和hashCode。
[!NOTE]
因为java泛型机制,为了保证类型安全,泛型必须进行类型检查,而int只是地址和值,无法进行类型检查,故泛型采用包装类。
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(1);
list.add(2);
Collections.sort(list);
System.out.println(list);转换中的应用
在Java中,基本类型和引用类型不能直接进行转换,必须使用包装类来实现。例如,将一个int类型的值转换为String类型,必须首先将其转换为Integer类型,然后再转换为String类型。
int i = 10;
Integer integer = new Integer(i);
String str = integer.toString();
System.out.println(str);集合中的应用
Java集合中只能存储对象,而不能存储基本数据类型。因此,如果要将int类型的数据存储在集合中,必须使用Integer包装类。例如,假设我们有一个列表,我们想要计算列表中所有元素的和。如果我们使用基本数据类型int,我们需要使用一个循环来遍历列表,并将每个元素相加。但是,如果我们使用Integer包装类,我们可以直接使用stream()方法来计算所有元素的和。
[!IMPORTANT]
例如hashmap需要实现了hashCode的类作为键值,而包装类在内部实现了hashCode。
List<Integer> list = new ArrayList<>();
list.add(3);
list.add(1);
list.add(2);
int sum = list.stream().mapToInt(Integer::intValue).sum();
System.out.println(sum);#Integer相比int有什么优点?
int是Java中的原始数据类型,而Integer是int的包装类。
Integer和 int 的区别:
- 基本类型和引用类型:首先,int是一种基本数据类型,而Integer是一种引用类型。基本数据类型是Java中最基本的数据类型,它们是预定义的,不需要实例化就可以使用。而引用类型则需要通过实例化对象来使用。这意味着,使用int来存储一个整数时,不需要任何额外的内存分配,而使用Integer时,必须为对象分配内存。在性能方面,基本数据类型的操作通常比相应的引用类型快。
- 自动装箱和拆箱:其次,Integer作为int的包装类,它可以实现自动装箱和拆箱。自动装箱是指将基本类型转化为相应的包装类类型,而自动拆箱则是将包装类类型转化为相应的基本类型。这使得Java程序员更加方便地进行数据类型转换。例如,当我们需要将int类型的值赋给Integer变量时,Java可以自动地将int类型转换为Integer类型。同样地,当我们需要将Integer类型的值赋给int变量时,Java可以自动地将Integer类型转换为int类型。
- 空指针异常:另外,int变量可以直接赋值为0,而Integer变量必须通过实例化对象来赋值。如果对一个未经初始化的Integer变量进行操作,就会出现空指针异常。这是因为它被赋予了null值,而null值是无法进行自动拆箱的。例如,如果我要区分未赋值和赋值,就可以用包装类。
[!NOTE]
优点:
可以存null值,表示没有赋值。
包装类在内部实现了hashCode,内部实现了比较接口
Comparable,可用于集合和泛型。各种便捷方法
()# 那为什么还要保留int类型?
包装类是引用类型,对象的引用和对象本身是分开存储的,而对于基本类型数据,变量对应的内存块直接存储数据本身。
因此,基本类型数据在读写效率方面,要比包装类高效。除此之外,在64位JVM上,在开启引用压缩的情况下,一个Integer对象占用16个字节的内存空间(12字节对象头和4字节的int值),而一个int类型数据只占用4字节的内存空间,前者对空间的占用是后者的4倍。
在循环中处理一个包装类,会频繁装箱和拆箱,反复触发GC,所以也建议在循环中使用int。
也就是说,不管是读写效率,还是存储效率,基本类型都比包装类高效。
#说一下 integer的缓存
Java的Integer类内部实现了一个静态缓存池,用于存储特定范围内的整数值对应的Integer对象。
默认情况下,这个范围是-128至127。当通过Integer.valueOf(int)方法创建一个在这个范围内的整数对象时,并不会每次都生成新的对象实例,而是复用缓存中的现有对象,会直接从内存中取出,不需要新建一个对象。
1.2 变量
()标识符的命名规则。
标识符的含义:是指在程序中,我们自己定义的内容,譬如,类的名字,方法名称以及变量名称等等,都是标识符。
命名规则:(硬性要求)标识符可以包含英文字母,0-9的数字,$以及下划线。标识符不能以数字开头 标识符不是关键字
命名规范:(非硬性要求)类名规范:首字符大写,后面每个单词首字母大写(大驼峰式)。 变量名规范:首字母小写,后面每个单词首字母大写(小驼峰式)。方法名规范:同变量名。
1.3 语句
()switch语句为什么不可以使用viewId?(安卓问题)
因为 switch 语句必须使用编译时常量。常量分为两种:编译时常量和运行时常量。编译时常量在编译时就确定值;而运行时常量在编译时不确定,在运行时才确定值。而 viewId 在安卓4.1时就不再使用final关键字修饰了,也就是从编译时常量变成了运行时常量。扩展:如bufferKinife因为在注解中使用了viewId,类型不再安全,故现在已经不再维护了。
- 性能优化
switch语句的底层实现依赖跳转表(Jump Table)。编译器需要为每个case生成确定的索引(如tableswitch或lookupswitch指令),这要求所有case值在编译时已知。若使用运行时常量,编译器无法提前生成高效的跳转逻辑,可能导致性能下降或冗余的条件判断。 - 确定性检查
编译时常量确保所有case值在编译时唯一且无冲突。例如,若两个case标签具有相同的值,编译器会直接报错。若允许运行时常量,潜在的重复值只能在运行时暴露,增加调试难度。 - 类型安全
编译时能严格校验case值的类型是否与switch表达式兼容(如String、enum或基本类型)。运行时常量可能因动态计算导致类型不匹配,引发运行时异常。
在 Kotlin 中,when 语句(类似于 Java 的 switch)对资源 ID 的支持更好。Kotlin 的 when 语句没有 Java switch 的编译时常量限制,因此可以直接使用 R.id.xx。例如:
when (view.id) {
R.id.button1 -> { /* 处理 button1 的逻辑 */ }
R.id.button2 -> { /* 处理 button2 的逻辑 */ }
else -> { /* 默认逻辑 */ }
}()扩展问题:为什么viewId 在安卓4.1时就不再使用final关键字修饰了?
因为安卓开始使用了组件化编程,不同组件之间有可能会出现id重复,故让它变成了运行时常量。所以你会在一些老的代码中看到switch语句中使用了ViewId值,这也是正确的。
在当时的开发者看来ButterKnife不得不说是一个神器,以至于到后来成了Android项目开发的标配。
后来,随着Android Studio的诞生,Eclipse开发Android项目逐渐淡出历史舞台。 Android studio的出现,带来了全新的技术,模块化风靡一时。 大概在这个时候,Google官方似乎就已经有了改造R类的想法。 在Android项目的library模块中,生成R类中的成员变量就已经改为了非final修饰。 同时,Google官方也不再建议在app模块的代码中使用像:这样的代码。switch(view.getId())
正如Android studio官网文档**《Non-constant Fields in Case Labels》**上给出的原因:
换句话说,常量在库项目中不是 final。原因很简单:当合并多个库项目时,字段的实际值(必须是唯一的)可能会发生冲突。在 ADT 14 之前,所有字段都是最终字段,因此,每当使用时,所有库都必须重新编译其所有资源和关联的 Java 代码以及主项目。这对性能不利,因为它会使构建变得非常缓慢。它还阻止了分发不包含源代码的库项目,从而限制了库项目的使用范围。
就是说,虽然viewId是编译时常量,但是当多模块时,由于构建的时间和个数不确定,前边的模块已经构建好了,导致后边构建的模块,仍然有可能重复id,所以多模块构建就需要把所有模块重新构建一遍,以保证ID不重复,这样会导致构建效率下降,而且也违反了模块化编程的初衷,故取消了final修饰。
在 Kotlin 中,when 语句(类似于 Java 的 switch)对资源 ID 的支持更好。Kotlin 的 when 语句没有 Java switch 的编译时常量限制,因此可以直接使用 R.id.xx。例如:
when (view.id) {
R.id.button1 -> { /* 处理 button1 的逻辑 */ }
R.id.button2 -> { /* 处理 button2 的逻辑 */ }
else -> { /* 默认逻辑 */ }
}这一改变直接致使ButterKnife无法在Android项目的library模块中使用。 而此时,ButterKnife正是如日中天,追随的开发者不计其数。 为了能够让ButterKnife运行在library模块,ButterKnife的作者Jake Wharton大佬曲线救国,通过生成R2类让ButterKnife在library模块中复活,并且得以发展壮大。 但不得不说,此时的ButterKnife 就已经埋下了深深的隐患,并导致了其最终的溃败。
就一个final字段,最终导致了ButterKnife 的彻底弃用。
1.4 字符串 String
()StringBuffer 和 StringBuilder
频繁进行字符串拼接,推荐使用这两个方法。StringBuffer 线程安全,StringBuilder线程不安全,根据不同使用场景选择。
底层都继承自AbstactSAtringBuilder,采用了可变字符数组。
()StringBuffer和StringBuild区别是什么?
区别:
- String 是 Java 中基础且重要的类,被声明为 final class,是不可变字符串。因为它的不可变性,所以拼接字符串时候会产生很多无用的中间对象,如果频繁的进行这样的操作对性能有所影响。String创建后,会在堆中的字符串常量池中进行缓存,如果存在缓存则直接返回。在JDK6以前,采用字符数组储存字符串;JDK8采用byte数组储存,并且加上字符编码的方式。因为考虑到大多数字符都是1个byte,而少数字符才是2个byte。
- StringBuffer 就是为了解决大量拼接字符串时产生很多中间对象问题而提供的一个类。它提供了 append 和 add 方法,可以将字符串添加到已有序列的末尾或指定位置,它的本质是一个线程安全的可修改的字符序列。在很多情况下我们的字符串拼接操作不需要线程安全,所以 StringBuilder 登场了。
- StringBuilder 是 JDK1.5 发布的,它和 StringBuffer 本质上没什么区别,就是去掉了保证线程安全的那部分,减少了开销。
()深入扩展,java的字符串为什么要设计成不可变的?
1. 安全性(Security)
- 防止意外修改:字符串广泛用于文件路径、网络连接、类加载等关键操作。若字符串可变,恶意代码可能篡改其内容,导致安全漏洞。例如,若一个文件路径被修改,可能指向未授权的资源。
- 权限验证:若字符串作为安全凭证(如密码)传递,不可变性防止其在验证后被修改,避免绕过安全检查。
2. 线程安全(Thread Safety)
- 无需同步:不可变对象天生线程安全,多个线程共享字符串时无需加锁,简化了并发编程,提升了性能。
- 避免竞态条件:若字符串可变,多线程环境下需处理复杂的同步问题,而不可变性消除了这一风险。
3. 字符串池优化(String Pool Efficiency)
内存复用:JVM通过字符串池(String Pool)缓存字面量,相同内容的字符串共享同一对象,减少内存开销。例如:
String s1 = "Java"; String s2 = "Java"; // s1和s2指向池中同一对象避免副作用:若字符串可变,共享同一对象的变量可能互相影响,破坏程序的正确性。
4. 哈希码缓存(Hash Code Caching)
- 性能提升:
String类内部缓存哈希码(hash字段),因其不可变,哈希值只需计算一次,后续直接复用。这对HashMap、HashSet等依赖哈希码的集合类至关重要。 - 稳定性保障:若字符串可变,作为键时修改内容会导致哈希码变化,破坏哈希表的完整性。
5. 类加载与反射机制(Class Loading and Reflection)
- 类名一致性:类加载器通过字符串名称加载类,不可变性确保类名在加载过程中不被篡改,保障JVM的正确性。
- 反射安全:反射API依赖字符串标识方法或字段名,不可变性避免关键信息被意外修改。
1.5 基础关键字
()instanceof 关键字的作用
instanceof严格来说是java中的一个双目运算符,用来测试一个对象是否为一个类的实例,用法为:
boolean result = obj instanceof Class其中 obj 为一个对象,Class 表示一个类或者一个接口,当 obi为 Class 的对象,或者是其直接或间接子类,或者是其接口的实现类,结果result 都返回 true,否则返回false。
注意:编译器会检査 obj是否能转换成右边的class类型**,如果不能转换则直接报错**,如果不能确定类型!,则通过编译,具体看运行时定。
int i = 0;
System.out.println(i instanceof Integer);//编译不通过i必须是引用类型,不能是基本类型
System.out.println(i instanceof object);//编译不通过
Integer integer = new Integer(1);
System.out.println(integer instanceof Integer);//true
//在 JavaSE规范 中对 instanceof 运算符的规定就是:如果 obj为 nu11,那么将返回 false。
System.out.println(null instanceof object); // false1.6 其他
#有一个学生类,想按照分数排序,再按学号排序,应该怎么做?
可以使用Comparable接口来实现按照分数排序,再按照学号排序。首先在学生类中实现Comparable接口,并重写compareTo方法,然后在compareTo方法中实现按照分数排序和按照学号排序的逻辑。
public class Student implements Comparable<Student> {
private int id;
private int score;
// 构造方法和其他属性、方法省略
@Override
public int compareTo(Student other) {
if (this.score != other.score) {
return Integer.compare(other.score, this.score); // 按照分数降序排序
} else {
return Integer.compare(this.id, other.id); // 如果分数相同,则按照学号升序排序
}
}
}然后在需要对学生列表进行排序的地方,使用Collections.sort()方法对学生列表进行排序即可:
List<Student> students = new ArrayList<>();
// 添加学生对象到列表中
Collections.sort(students);#Native方法解释一下
在Java中,native方法是一种特殊类型的方法,它允许Java代码调用外部的本地代码,即用C、C++或其他语言编写的代码。native关键字是Java语言中的一种声明,用于标记一个方法的实现将在外部定义。
在Java类中,native方法看起来与其他方法相似,只是其方法体由native关键字代替,没有实际的实现代码。例如:
public class NativeExample {
public native void nativeMethod();
}要实现native方法,你需要完成以下步骤:
- 生成JNI头文件:使用javah工具从你的Java类生成C/C++的头文件,这个头文件包含了所有native方法的原型。
- 编写本地代码:使用C/C++编写本地方法的实现,并确保方法签名与生成的头文件中的原型匹配。
- 编译本地代码:将C/C++代码编译成动态链接库(DLL,在Windows上),共享库(SO,在Linux上)
- 加载本地库:在Java程序中,使用System.loadLibrary()方法来加载你编译好的本地库,这样JVM就能找到并调用native方法的实现了。